Parallel Computing Mandelbrots
Posted: July 10, 2016
Updated: April 21, 2026
Introduction
A Mandelbrot is an image that is created by the calculation z = z^2 + c. This page was created to experiment with creating Mandelbrots with parallel computing, either with an SIMD vector unit of a CPU or using multiple cores to create the image.
There are some performance numbers on this page for the different platforms. The speed of C code is sometimes dependant on the C compiler, and it's possible some platforms may not have the best C optimizations. The assembly code sometimes could possibly be improved since sometimes the code is unoptimized to either make it easier to read or to match closer to the way the x86 code works.
So far there are examples on the following platforms:
- Intel x86_64 SSE vector unit
- Intel x86_64 AVX2 vector unit
- Intel x86_64 AVX-512 vector unit
- Parallax Propeller FLiP (8 core)
- Parallax Propeller 2 P2 Edge (8 core)
- Playstation 3 with both AltiVec and Cell SPUs
- Playstation 2 on vector unit VU0
- Nvidia Jetson Nano using CUDA
- Parallella board (16 core Epiphany chip)
- Raspberry Pi 4 Kubernetes Cluster
More chips / platforms could be added later...
Related Projects @mikekohn.net
| Mandelbrots: | Mandelbrots SIMD, Mandelbrot Cluster, Mandelbrot MSP430 |
| ASM: | SSE Image Processing, JIT Compiler, ARM Assembly, Easy Match, Mandelbots With SIMD |
Intel x86_64 SSE
Added July 10, 2016
Since Intel x86 has an SIMD (single instruction, multiple data) instruction set called SSE, it's possible to load a 128 bit register with either four 32 bit integers or four 32 bit floats (or some other configurations of data) and run math operations on all 4 elements in the register in parallel. It is possible to do Mandelbrots using integer operations, which might be be faster than floating point, but I decided to do this with floating point.
To start with, the code was written in standard C and later converted to pure assembly using SSE instructions. Most of the code is pretty straight forward except for one thing. When a pixel has gone out of range of the Mandelbrot set (when the sqrt(z^2) > 2) then that pixel needs to stop counting down. This was done by having a increment vector that starts out as the four integers [ 1, 1, 1, 1 ] stored in the register xmm2. Using the cmpleps instruction, if any element of the vector is bigger than 4 (the sqrt part can be avoided here) then the count element for that pixel is set to 0. If all counts are set to 0 the main loop is aborted. Since the 4 pixels being calculated are near each other, they are probably going to finish at similar times.
The performance difference is pretty decent. The second picture below rendered on an AMD FX-8320 CPU:
| Standard C: | 0.380 seconds |
| SSE Assembly: | 0.107 seconds |
Using 8 cores with the multithreaded version of the program:
| Standard C: | 0.065 seconds |
| SSE Assembly: | 0.021 seconds |
Source Code:
git clone https://github.com/mikeakohn/mandelbrot_sse.git
Intel x86_64 AVX2 / AVX-512
Added November 17, 2018
I added to the mandelbrot_sse.git repository code to use AVX2 to compute the same Mandelbrot. AVX adds 256 bit ymm registers supporting floating point SSE instructions. AVX2 adds integer instructions and newer AVX-512 adds 512 bit zmm registers along with some masking registers that gives AVX capability similar to the Playstation 2's .xyzw flags.
Testing on an Intel Xeon Platinum 8168 CPU @ 2.7GHz (Skylake) I get the following results:
| Standard C: | 0.33 seconds |
| SSE (128 bit) Assembly: | 0.092 seconds |
| AVX2 (256 bit) Assembly: | 0.052 seconds |
| AVX-512 (512 bit) Assembly: | 0.033 seconds |
One thing interesting, AVX-512 bit can calculate 16 pixels at the same time. A speed increase for that could be to load the 512 bit register as a 4x4 pixel matrix. Currently the register is loaded directly as a single line, which means if vector element 0 is a red pixel (quickly calculated as not being in the Mandelbrot set) and pixel 15 is a black pixel, pixels 0 to 15 will all have to go through all 128 iterations. In the straight C version the red pixels would have stopped calculating earlier.
There are probably still more ways to optimize the code so I'll probably eventually update it more.
ARM64
Added May 26, 2024
I started adding ARM64 support to naken_asm a while back. After getting through about 15 instructions I got frustrated and thought "life is too short". But I really wanted to try ARM64 SIMD (NEON instructions) so I decided to see if I could put enough instructions in there to do this Mandelbrot project. There's actually some pretty decent ARM64 support now, but not everything.
I have some really mixed feelings about ARM64. After working on the assembler I feel like asking the question: Is this really RISC? All the instructions are 32 bit wide like a typical RISC, but it has addressing modes that compete with the complexity of the x86. The bits in each lane of the opcodes have very different meanings even if the opcodes have a similar function. It seems like there are a lot of missed opportunities for taking advantages of patterns to make the CPU simpler.
On top of all that the assembler syntax was just... not fun. Not fun to implement in the assembler. The assembly I originally wrote for the Mandelbrot was very difficult to read. When I finally moved to Apple Silicon to test it, I realized their objdump used a much cleaner syntax, so I change naken_asm to support it too. An example is, on the Raspberry Pi 5 with GNU syntax:
fadd v6.4s, v6.4s, v7.4s
Gets disassembled (and can be assembled) on the Mac devtools as:
fadd.4s v6, v6, v7
The standard ARM64 syntax is like a Where's Waldo puzzle. It's redundant and makes writing an assembler difficult because each of those registers have to be parsed and then checked to make sure all 3 registers are of the same type.
The mandelbrot_simd.asm file was created by copying the x86 SSE code and converting it to to ARM64 (aarch64) SIMD. I left the x86 code in, but commented out. The speed improvement was a little disappointing. I thought maybe it was because instructions were possibly too close. I've read on Playstation 2 and seen on Playstation 3 (shown further down on this page) that if code is space out so the destination of an operation isn't used immediately, due to pipelining, it can speed up processing. I tried spacing some instructions out here, but it didn't seem to make a difference. Maybe they have less execution units so each instruction doesn't do 4 operations in 1 shot (I believe some old x86's did this)? Not sure.
The following platforms were tested: an older Nvidia Jetson Nano (Ubuntu 18.04), Raspberry Pi 3 (Ubuntu 24.04), Raspberry Pi 4 (Ubuntu 23.10), Raspberry Pi 5 (Ubuntu 23.10), Apple Silicon M2, and Apple Silicon M3. The version of gcc could make a difference on the C performance, but wouldn't affect the SIMD.
| C | SIMD | |
| Nvidia Jetson | 1.03s | 0.32s |
| Nvidia Jetson Orin | 0.46s | 0.17s |
| Raspberry Pi 3 | 1.96s | 0.68s |
| Raspberry Pi 4 | 0.66s | 0.25s |
| Raspberry Pi 5 | 0.26s | 0.11s |
| OrangePi 5 Plus (Rockchip RK3588) | 0.28s-0.33s | 0.11s-0.16s |
| Apple M2 | 0.26s | 0.10s |
| Apple M3 | 0.23s | 0.09s |
| Apple M5 | 0.16s | 0.07s |
Here's a video of 5652 frames calculated on a Raspberry Pi 4 cluster using the same ARM64 assembly code:
RISC-V
I'm still waiting on a RISC-V board I can afford that has a chip with the 1.0 version of the vector instructions.
Update: I have a RISC-V board that supposedly has the 1.0 instructions. Just need to find time to implement it.
Parallax Propeller FLiP
Added July 7, 2017
I ended up getting a Propeller FLiP module along with a 96x64 OLED display from Parallax's website so I decided to test some Mandelbrots on this platform. First two things to note about the FLiP: it doesn't have hardware SPI so it takes a bunch of code to write to the OLED display and it doesn't have a hardware multiply instruction so I had to write a small routine in software. The SPIN software SPI is quite slow (as can be seen in the video when the screen fills with green). The Java code can render a Mandelbrot and draw it at the same speed SPIN can write green all over the display.
The video above (as captioned) shows 3 different sets of software. The first program is a combination of SPIN (sets up the LCD and fills the screen with green) and then loads a Mandelbrot program that was written in Java and compiled further to native Propeller using Java Grinder. All the code is in the samples directory of the Java Grinder git repository. As a side comment, it doesn't show up very well in the video, but that little LCD is one of the nicest looking displays I've seen: 96 x 64 Color OLED Display Module.
The second program is written in pure assembly. Again the code is started up by a SPIN program and then control is transfered to the assembly program. The source code for this program is in the naken_asm repository:
Source: samples/propeller/
The third program uses all 8 cores of the Propeller and it definitely shows. Core 0 runs some SPIN code which arbitrates what the other 7 cores do. Core 1 is just there to control the LCD. When Core 0's SPIN code signals it, it loads the image out of shared memory and writes it to the OLED display. When Core 0 wants to render a Mandelbrot, it signals Core 2 to 7 the real and imaginary coordinates of a single line in the Mandelbrot set. Each core writes to the shared memory segment that the LCD uses to write to the OLED display. The SPIN code constantly looks for a free core to give coordinates to until there are no more lines to render and then just simply waits until they finish and tells Core 1 to draw.
Parallax Propeller 2
Added January 2, 2021
Last month I was able to get the new Propeller 2 chip on a P2 Edge card. The new chip has a modified instruction set so I added propeller2 support to naken_asm. The chip has some instructions that help with performance (hardware multiply) and can run up to 300MHz. I ended up running at 160MHz (just double the speed of the original propeller) just because I wasn't sure how fast the SPI would work on the OLED display. Since I used the same OLED display, I basically just converted the SPIN code to SPIN2 and converted the assembly code to PASM2 fixing some bugs from the original code too unfortunately. This chip is smoking fast as seen in the video below (compared to the video above):
Source: samples/propeller2/
Unfortunately, Parallax's development environment is all Windows based so I had to run their IDE on Linux with WINE. Unfortunately I couldn't get WINE to see the serial port, but I was able to use loadp2 to upload the code to the chip:
./loadp2 -p /dev/ttyUSB0 ~/.wine/drive_c/mandelbrot.binary
I haven't added Propeller 2 to Java Grinder yet, but since it seems like it might be as easy as extending the Propeller code and overriding some functions, I may do that sometime in the future.
Playstation 3
Added October 21, 2017
Ever since I got a Playstation 3 (and installed Linux on it) I've been wanting to try out some software development on it. Within the past year I added PowerPC and Cell to naken_asm and in the past couple weeks I finally got some time to try it out. Last weekend I started out by writing Mandelbrot code using the AltiVec instructions and this weekend I translated the code to Cell so it could run on the 6 available SPUs.
The AltiVec code (linked to below) was pretty much a direct translation of the Intel SSE code I did earlier. It's kind of interesting the difference between the two instruction sets. There were a few things the AltiVec could actually do in less instructions, especially since Intel usually only has 2 operands since the destination is always operated on. The AltiVec (and PowerPC in general) always has a destination register along with the two registers operated on. Saves the programmer sometimes from having to save registers that might be used multiple times and would be destroyed after being used in the Intel version.
Another interesting thing I found, the AltiVec version was originally taking around 1.09 seconds to run. I was able to comment out 5 instructions above the "beq exit_mandel" which used system memory to check if a value was 0. I'm not 100% sure why, I'm guessing the vcmpgtfpx instruction is setting the PowerPC's status register so the beq works without the lines above, but either way, with those 5 instructions gone, it almost doubles in speed. It seems memory access on the Playstation 3 might be pretty lousy? Or is there something else going on?
So now the Cell code. Each Cell has its own 256k SRAM memory segment so memory writes should be a lot faster. The code is written so the PowerPC core will tell an SPU (Cell) core to calculate a single line in the Mandelbrot image and when it's finished the PowerPC will have the SPU transfer the computed data into the correct memory location inside of the picture in main memory. To increase the speed of calculation I used a ring buffer inside the SPU so that while the image is being transferred from the SPU to main memory, the SPU can start calculating the next line. With a single SPU this increased the speed from about 0.55 seconds to render an image to 0.48 seconds. I got an even bigger speed increase when I used the hbra (branch prediction) instruction to tell the SPU that the for_x and mandel_for_loop branches were most likely to happen. The speed increase went from about 0.48 seconds on the single code to about 0.36 seconds. With 6 SPUs it dropped from around 0.110 seconds to about 0.093 seconds. It's interesting the non-optimized Cell code on a single core is a bit faster than the AltiVec (probably due to SRAM vs system RAM). With all 6 SPU's running it's around 4x to 5x faster.
What I really didn't expect however was my AMD (Intel x86_64) based computer to beat the crap out of the Playstation 3. When I took out the code to transfer the image from the SPU to the PowerPC's main memory (before the optimization of the ring buffer and the branch prediction hints), the time drops to 0.079 seconds (0.44 seconds with 1 SPU). I've read that Linux on Playstation 3 is virtualized, but I wouldn't expect that to affect memory performance. If anyone can give me some information on possibly what's going on, please send me an email.
Update October 24, 2017: I think I may have a better clue of what's going on with the performance difference. A couple days ago I reordered the instructions trying to make it so the result of an instruction is not used for at least 1 instruction. That got a pretty good speed increase. The next day I tried doubling the the number of calculations done per row. The new code computes 8 pixels at a time instead of 4 using 2 sets of registers. This put the result of instructions (the destination register) even further away. In other words, if there is fa r1, r2, r2 (floating point add r2 + r2 putting the result in r1), the r1 register won't be used as a source register for at least 1 or 2 instructions now. The assembly code looks really ugly, but it's faster by quite a bit. One SPU is now almost the speed of the SSE on a single core. I did some more digging and it seems the instruction latency is higher in the Playstation 3 Cell than the AMD chip... so that probably explains most of the slowdown. Makes me wonder how many execution units (how many floating point operations) each chip can really do simultaneously.
Update January 1, 2020: After doing Mandelbrots on CUDA, I'm tempted to revisit the Playstation 3, doing it the same way I did it on CUDA... dividing the screen into 6 sections and having each SPU do 1 section with less signalling. Would probably have to interlace it so each core does a more even amount of work.
Source Code:
mandelbrot_altivec.asm
mandelbrot_spe.asm
mandelbrot.c
| Standard C: | 1.818 seconds |
| AltiVec Assembly: | 0.660 seconds |
| SPU Assembly (1 core): | 0.368 seconds |
| SPU Assembly (6 cores): | 0.093 seconds |
| After reordering | |
| SPU Assembly (1 core): | 0.304 seconds |
| SPU Assembly (6 cores): | ~0.083 seconds (varies a lot between 0.074 to 0.087 or so) | After reorderings / rendering 8 pixels at a time |
| SPU Assembly (1 core): | 0.190 seconds |
| SPU Assembly (6 cores): | ~0.073 seconds (it went as low as 0.065 seconds) |
Playstation 2
Added August 6, 2018
I recently completed a demo of a program written in Java running on a Playstation 2. As part of the demo there is a Mandelbrot being generated in real-time on vector unit VU0 while other vector unit is doing 3D transformations while the MIPS orchestrates it all.
The instruction set in the Playstation 2 vector units is pretty interesting. It's VLIW, so each instruction is 64 bits which is divided into two 32 bit instructions. The first instruction is called the upper (which does pretty much all the FPU vector unit instructions) and the lower (which does mostly integer unit and load / store). Both instructions should run at the same time. Unfortunately, with the Mandelbrot code I wrote, most of the time I couldn't match an upper and lower instruction so there are a lot of NOP's all over the code.
This vector unit also has extra flags on the FPU instructions to tell the CPU which elements of the vector will be changed. So if vf05 = [ 1.0, 2.0, 3.0, 4.0 ] and vf06 = [ 5.0, 6.0, 7.0, 8.0 ]... when the instruction is add.xy vf05, vf05, vf06 then after the instruction executes, vf05 = [ 6.0, 8.0, 3.0, 4.0 ].
The VU1 vector unit has some extra instructions (and extra data RAM and instruction RAM).. ESIN, ESQRT, etc. The instruction missing that would have helped here is the ESUM, which adds all 4 elements of the vector and stores it in the P register. It's an 11/12 cycle instruction which I implemented with 7 instructions. Actually, each one of these instructions run in 1/1 cycles so it's possible that using ESUM is actually slower. I guess a bigger advantage of ESUM is can run while other instructions run.
One instruction that's missing from both vector units (that oddly exists in the main R5900 Playstation 2 CPU) is a compare instruction. I needed to create a bitmask for each element of the vector depending on if the calculated value passes 4.0 so that piece of the vector would stop counting. Playing with the numbers I came up with a way of making each vector element a 0 or 1 depending on if it's past 4 or not. That can then be multipled to the count vector to make that element stop counting:
def less_than_4(num):
a = min(4.0, num)
a = a - 4.0
a = a * -32768.0
a = min(a, 1)
print "result=" + str(int(a))
The code isn't optimized. I was wanting to keep this one easier to read and I didn't feel like timing this one anyway. The code could have been sped up the same way as the Playstation 3... by using more registers and calculating more than 4 pixels at a time. The FPU instructions have a throughput of 1 and latency of 4. So since most of the operations use the destination register as a source in the next instruction, the CPU will stall for 4 cycles.
Source: mandelbrot_vu0.asm
Nvidia Jetson Nano Using CUDA
Added January 1, 2020
I recently got one of these Nvidia Jetson Nano boards to learn CUDA on. This board runs Linux with four 64 bit ARM cores (1.43 GHz), 4 GB RAM, and 128 core Maxwell GPU. I updated the x86_64 version of the single threaded Mandelbrot generator to run as straight C, 1 CUDA core, and all 128 CUDA cores. My results came out as:
| Standard C: | 1.06 seconds |
| CUDA (1 Core) | 7.6 seconds |
| CUDA (128 Cores) | 0.075 to 0.27 seconds |
Pretty interesting that a single ARM core was beating the GPU core by quite a bit. With all 128 GPU cores it beats out the ARM, but still not as fast as a single core on the Intel Skylake CPU with AVX2.
With the other systems, such as the Playstation 3 and Parallella, I had the main CPU arbitrate to each of the processing cores 1 line of the Mandelbrot picture. The reason why I did this is because adjacent lines in the Mandelbrot set would probably take approximately the same amount of time. There's a signaling overhead involved with it, but it keeps all the cores evenly busy.
With the CUDA version, I simply divided the display into 128 section so each core would only compute 6 lines. This means that the core that computes an area with more black pixels will take more time than the other cores. I was going to do it the Playstation 3 way, but I could find a good way to do signaling between the CPU and GPU. It seems that if the CPU reads global GPU memory it causes page faults and such... probably quite slow.
Parallella (Epiphany III)
Added May 28, 2017
A couple years ago I added Epiphany support to naken_asm but I never had a chance to test it. I recently aquired a Parallella board so I decided to try Mandelbrots with it.
The source code is included in the samples / epiphany directory in the naken_asm repository. The mandelbrot.asm file contains the Epiphany assembly code and the test_mandebrot.c has the host CPU (Zynq) source code. The test_mandelbrot.c program passes a real / imaginary coordinate to a non-busy core, signals the core with a USER interrupt, and waits for the core to set a "done" flag in the external shared memory area. Each core generates an entire row of the image before signaling it's ready for another data set to work on.
Update June 6, 2017: I added enough Epiphany / Parallella support to Java Grinder so that I could write the Mandelbrot code in Java and compile the byte code into Epiphany. It still uses the test_mandelbrot.c but uses Mandelbrot.java in the samples/epiphany directory to run on the Epiphany cores. Looks like the Java code is a more than 2x slower. It's possible I could optimize the output to run quite a bit faster.. but for now this will do. Java Grinder is still missing support (at the time of this writing) for arrays and stuff.. but it has support for reading / writing the shared memory.
The second picture below rendered on a Parallella Microserver at the following speeds:
| 1 Core (assembly): | 5.2 seconds |
| 16 Cores (assembly): | 0.32 seconds |
| 16 Cores (Java): | 0.78 seconds |
Some interesting things I found here: The Parallella's SDK has functions for accessing each core's local memory directly. I found that if I did this while the core was running, the core would sometimes go nuts. As soon as I moved to using all external RAM, it stopped doing that. I think using the local memory probably would get better performance overall, but I just couldn't get it working right. What's odd is the local memory of each core is divided into 4 parts, so I was keeping the code in 1 segment, the signaling (coordinates and done flag) in another segment, and the actual image in another. I tried moving the signalling to external memory keeping the image in faster local RAM, but it still crashed the core. I'm probably doing something wrong?
The Mandelbrot code is written in pure assembly using the floating point unit of the Epiphany. I was able to take advantage of the fused multiply / add and fused multiply / subtract instructions. To keep the code more dense (which should help it run faster), I made the most use of registers r0 to r7 in the parts of the code that does the most calculations. Those registers can fit into instructions that are only 16 bit in size.
The Epiphany is still slower than the x86_64 SSE code shown above, but then again this chip is only running around 667MHz where the x86_64 I used was 3.5GHz. Overall this is a really neat little board and I can't wait to do some more stuff with it.
Raspberry Pi 4 Kubernetes Cluster
Added January 8, 2022
Seemed like a separate page was more appropriate for that project: Mandelbrots Cluster.
Pictures

A standard Mandelbrot computed using SSE assembly code.
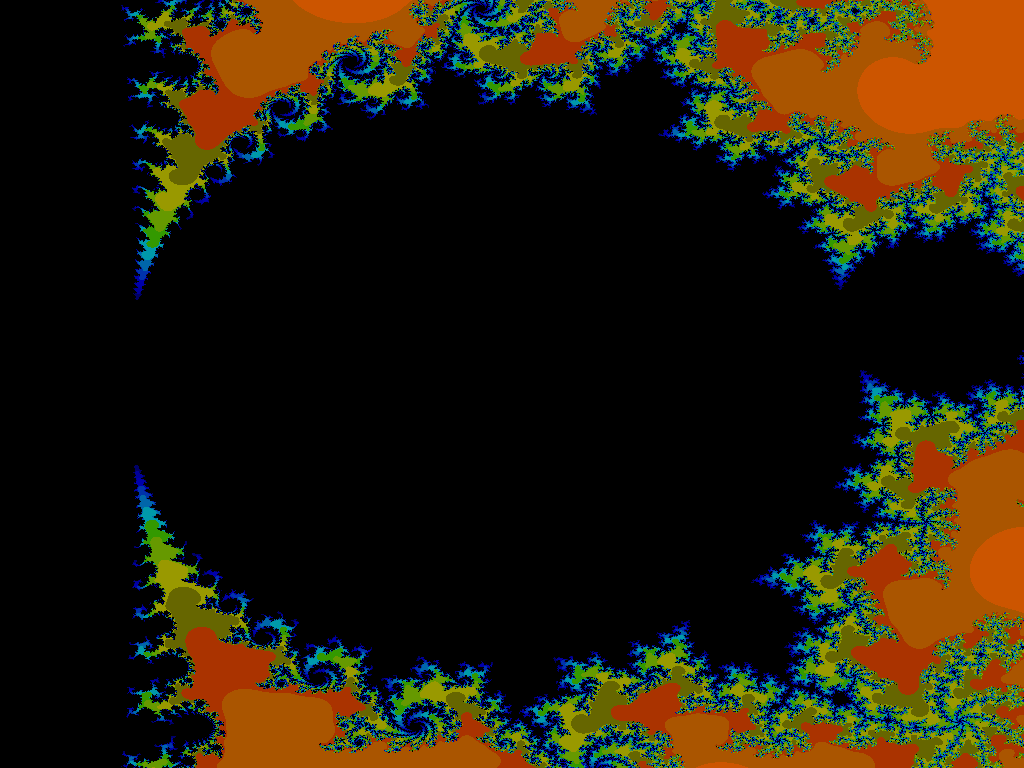
A Mandelbrot computed using SSE assembly code zoomed in.

Here is the Parallella board with a cheap little fan on top of it.
The chip seems to run around 54C or so with the fan. Without it,
it overheats while even trying to compile
naken_asm.
Copyright 1997-2026 - Michael Kohn
